The Russian National Corpus is a representative collection of texts in Russian, counting more than 2 bln tokens and completed with linguistic annotation and search tools



Search in corpora






News
The Russian National Corpus celebrates its 20th anniversary!
On April 29, 2004, the RNC website was opened for free access. But the creation of the RNC began much earlier, back in 2000. It is symbolic that the official "birthday" of the Corpus is on April 29 – the birthday of the Russian linguist, author of the Grammatical Dictionary of the Russian language A. A. Zaliznyak (1935-2017).
It all started with the idea of creating a complete collection of texts that would be culturally representative and reflect the diversity of prose written between 1965 and 2000. Currently, the RNC consists of 49 corpora with a total volume of more than two billion tokens. For 20 years, the Corpus has become an indispensable tool for linguists, teachers, students and anyone interested in the Russian language.
Congratulations to the creators of the RNC and those who help it develop! Thanks to you, the Corpus continues to grow and improve, providing new opportunities for learning the Russian language.
For those who are interested in learning more about the history and modern capabilities of the Corpus, we have prepared a set of materials:
- Explore how the corpus looked 20 years ago, in the RNC Museum.
- Immerse yourself in the history of the creation and development of the RNC in a special project of the “Bolshoy gorod”.
- Read the User Guide and learn how to use the corpus for different tasks.
- Explore the publications about the RNC in the recently updated section. We recommend paying attention to the recent publication on the fundamental reconstruction and modernization of the RNC platform.
- Download and apply neural network models, which are used to mark up words and texts of the Corpus, for your own tasks
- Find out how to get the offline version of the Corpus for research.
Those who want to participate in the development of the corpus are invited to join the group «Друзья НейроКРЯ». You will be the first to learn about upcoming projects and will be able to participate in them. Recently, we launched a new experiment to find out which definitions of words are better perceived by users: taken from dictionaries or generated by a neural network.

A new section is now available on the Corpus website. It describes the RNC neural network models used for annotating words and texts within the Corpus.
The users have access to the following tool:
- the tokenizer
- vector space models searching word associates and customized for 7 domains
- models for morphemic annotation
- models for annotating genre, topic, and type of text
The new section will be useful for everyone who is interested in natural language processing and wants to learn more about what machine learning technologies are used in RNC. Users can consult descriptions of the models or download them for their own use. Before downloading a model please read the license agreement and accept its terms.
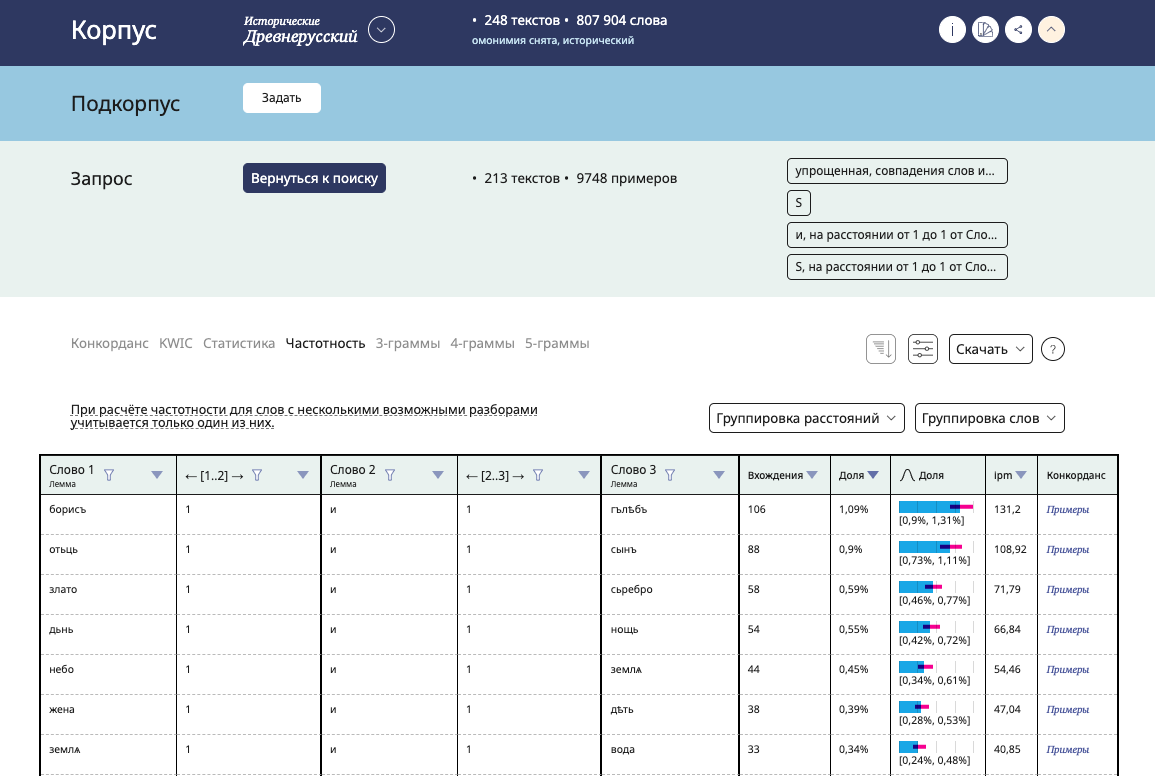
In April, the Old East Slavic corpus was considerably upgraded. It now features new types of search results, such as Frequency, Statistics, and n-grams. Using the Frequency feature users can build frequency lists of tokens and constructions. For example, one can check which nouns are coordinated most often in the corpus of the Early Medieval texts (‘Boris and Gleb’, ‘fear and trembling’ and others). The query results can be sorted by context. Frequency dictionaries are available while customizing subcorpus, and they can be compared to the lexical frequencies of the whole corpus.
The arrival of new functionality expands the possibilities of using the corpus and automates routine processes that previously took considerable time.
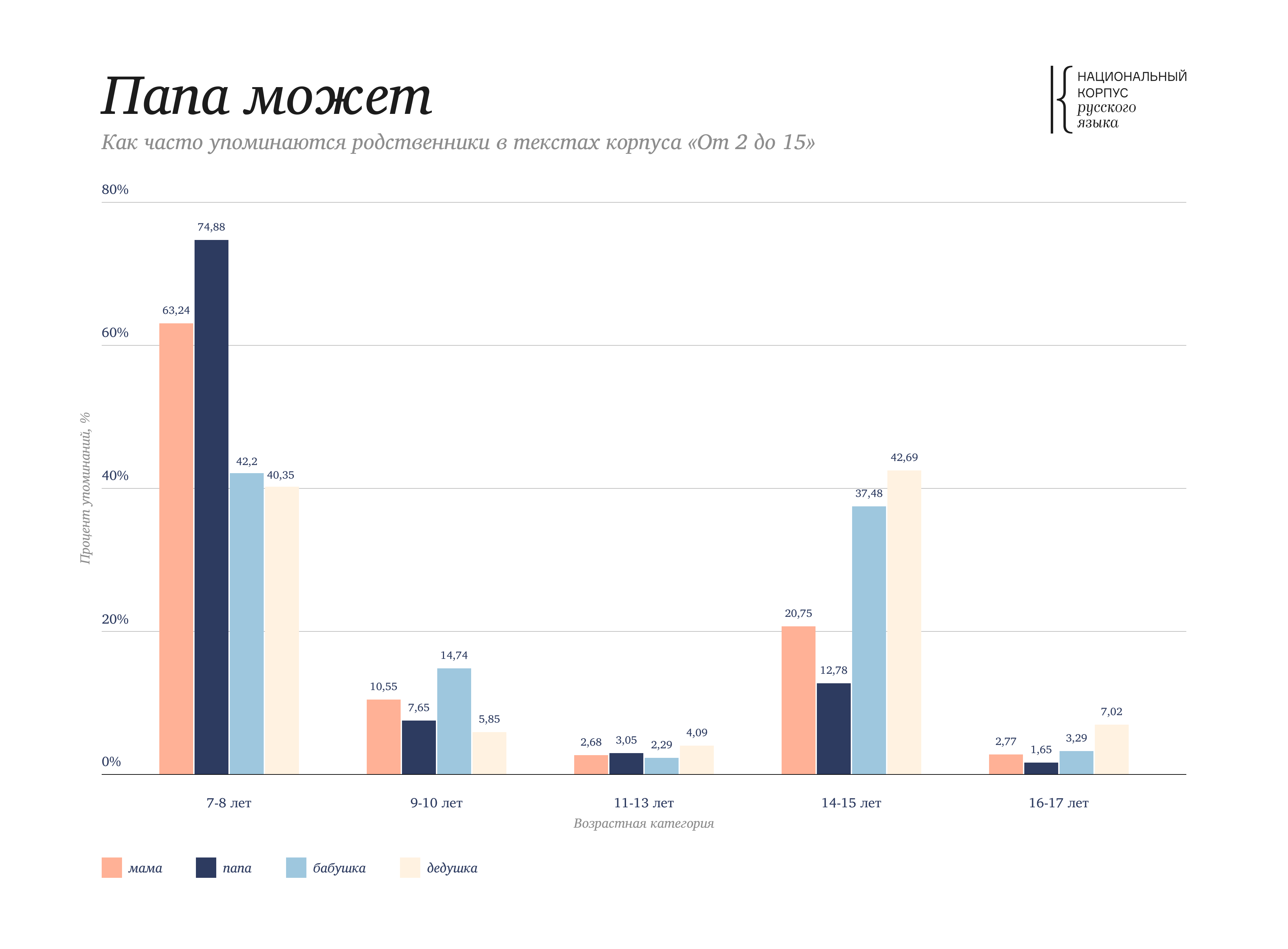
We continue to roll out new functionality already available in the advanced corpora, such as Main, Media, and Learning, to other corpora. An improved version of the “From 2 to 15” corpus is now available to users of the RNC. All the texts within the corpus feature resolved grammatical homonymy and syntactic annotation. Syntactic relations search and collocation search are now available, as well as new output types such as frequency, n-grams, statistics.
The Word at a Glance function has been updated, and new types of sorting by context have been added.
In the Word at a Glance you can see that the words мама 'mom' and папа 'dad' are used much more often in texts for the children of 7-8 years old, and the words бабушка 'grandma' and дедушка 'grandpa' has an equal frequency rating for both the children of 7-8 years and for teenagers of 14-15 years.
The bar next to the fragment indicating the age of readers who should understand these fragments is now clickable. When you click, you will see the calculated classical readability indices: Flesch-Kincaid Index, Coleman-Liau Index, Automatic Readability Index, Simple Measure of Gobbledygook, Dale-Chull readability formula.